
«Принёс посылку! Только я вам её не отдам! Потому что у вас доку́ментов нету.»
Печкин
Когда мы реализуем наши проекты, мы постоянно сталкиваемся с задачей ввода и распознавания различных документов – формализованных и неформализованных, построенных по каким-либо шаблонам, созданным по утверждённым формам. Одним из классов являются удостоверяющие личность документы. Этот особый класс документов стоит немного особняком – документы там достаточно формализованы, распознаваемых данных немного, присутствуют графические объекты, такие как подпись и фотография. Тексты на удостоверяющих документах слабо верифицируются по словарям, так как содержат фамилии, имена, топонимы, наименования пунктов выдачи. При этом, в распознавании удостоверяющих документов важна точность и минимизация ошибок, так как эти данные могут поступать напрямую в учётные системы.
Я неоднократно встречался со сценариями ввода различных удостоверений личности в информационные системы. Например, система выдачи пропусков:
- Сотрудник на внутреннем портале заказывает пропуск для посетителя. Заявка попадает в службу охраны.
- Когда посетитель приходит на проходную, то предъявляет удостоверение личности, его сканируют, система распознавания удостоверений личности извлекает из сканированного образа всё, что можно извлечь.
- По фамилии находится соответствующая заявка, автоматически печатается согласие на обработку персональных данных.
- Выдаётся пропуск. Заявка закрывается.
- В архиве сохраняется сканированный образ документа посетителя, данные удостоверения личности, время входа-выхода и так далее.
Также, распознавание удостоверяющих документов может быть использовано в банковской сфере, в присутственных местах, где требуется предъявление документов. Посетитель предъявляет паспорт или иное удостоверение, система распознавания определяет ключевые параметры документа:
- ФИО;
- номер, серию;
- дату выдачи, орган выдавший документ;
- MRZ – machine-readable zone (машинно-читаемая зона для паспортов) и др.
Клиент автоматически находится в базе данных, сравниваются его предыдущие данные с паспортными, изменения, производится проверка на корректность данных. При необходимости можно сравнивать или демонстрировать оператору фотографию с паспорта и фото, сохранённое ранее – это позволит повысить защиту от мошенничеств, связанных с подделкой документов (хотя и не исключит возможность подделки полностью, на 100%).
Автоматизация ввода удостоверяющих документов может быть внедрена в гостиницах, страховых компаниях, автосервисах, магазинах, туристических агентствах; в поликлиниках, особенно при оказании платных услуг; при продаже билетов, где требуется идентификация человека, например, продажа билетов на футбол. Сфера применения систем распознавания такого рода документов огромна, а внедрение таких решений значительно ускоряет обслуживание посетителя!
Данные паспортов могут автоматически контролироваться по соответствующим перечням органов внутренних дел, выдавших паспорт, номеру/серии паспорта и коду подразделения. Все эти вещи взаимосвязаны и могут быть автоматически проверены для контроля подлинности документа.
На российском рынке сегодня представлено два основных решения по распознаванию удостоверений личности:
- ABBYY PassportReader SDK. Комплексное решение от известного разработчика систем распознавания, компании Аби. http://www.passportreader.ru/
- Smart IDReader. Достаточно новое на рынке, встраиваемое решение от компании SmartEngines. http://smartengines.ru/smart-idreader/
Как мы тестировали
Для тестирования нами был создан стенд, представляющий собой веб-сайт, в котором можно было выбрать механизм распознавания; загрузить один или несколько образов; отсканировать документ и получить результаты. Приложение замеряло время полного цикла и непосредственно процесса распознавания образа.
Сайт был запущен на рабочей станции Intel i7 6700 4 core / 3.4GHZ / 32Gb RAM.
В общем, всё просто, ничего лишнего!
ABBYY PassportReader SDK
Данный продукт представляет собой инструмент разработчика Software development kit, предназначенный для встраивания в конечное решение заказчика. Возможно встраивание в двух вариантах:
- Встраивание в толстый клиент. Лицензируется каждое рабочее место;
- Развёртывание как веб-сервис. Лицензируется сервер.
Размер развёрнутого веб-сервис решения составляет 346 Мб.
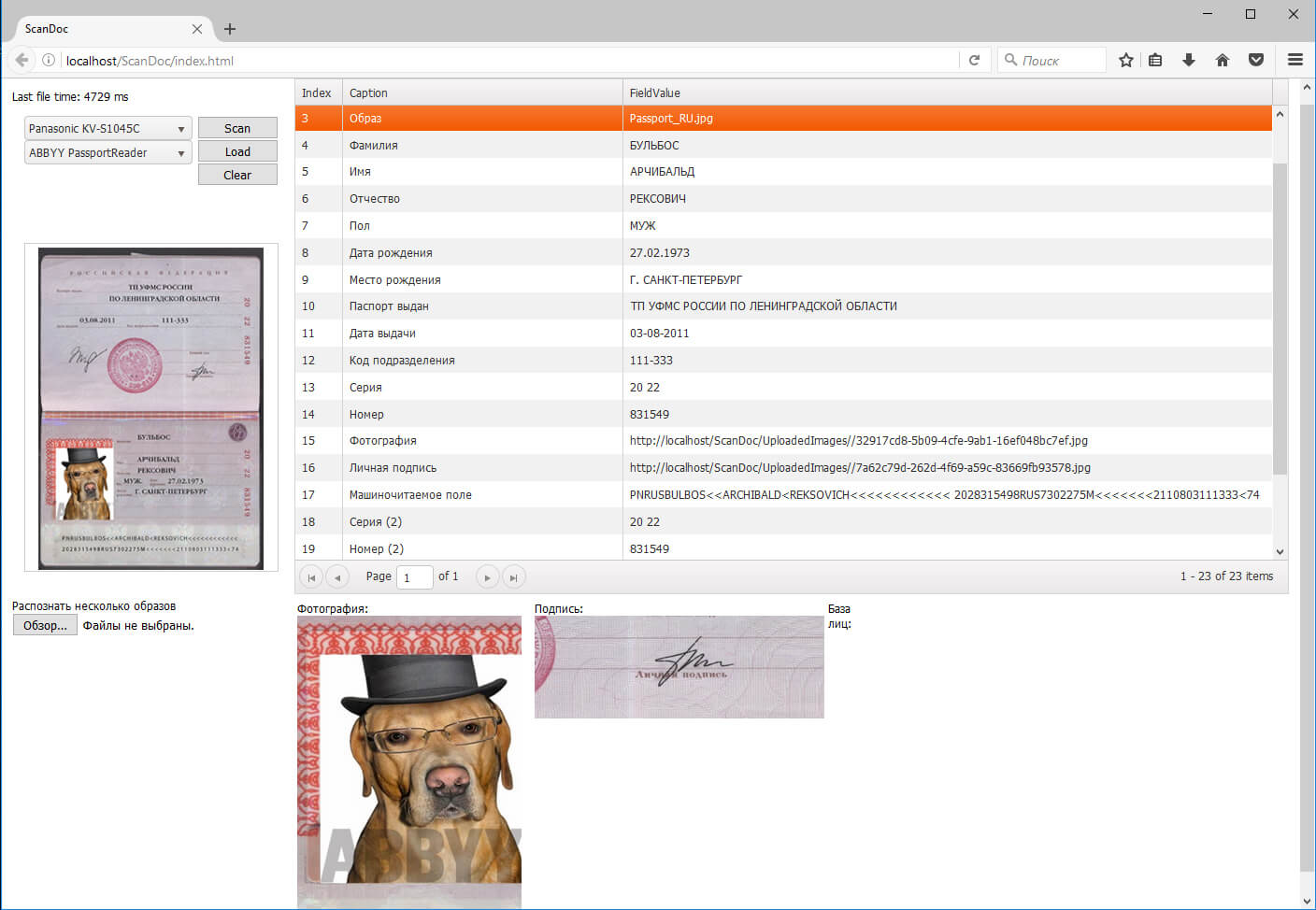
Для стенда нами был использован вариант развёртывания как веб-сервис. Обращение к веб-сервису распознавания удостоверений личности осуществляется по протоколу HTTP -SOAP из веб-сайта стенда.
ABBYY PR «из коробки» поддерживает различные удостоверения личности на нескольких языках, а также международный формат паспорта:
- Заграничный паспорт (универсальный шаблон);
- Паспорт гражданина Российской Федерации;
- Отдельные страницы паспорта гражданина Российской Федерации;
- Заграничный паспорт гражданина Российской Федерации;
- Водительское удостоверение гражданина Российской Федерации;
- Свидетельство о рождении гражданина Российской Федерации;
- Удостоверение личности гражданина Азербайджана;
- Заграничный паспорт гражданина Азербайджана;
- Паспорт гражданина Белоруссии;
- Удостоверение личности гражданина Казахстана;
- Заграничный паспорт гражданина Казахстана;
- Водительское удостоверение гражданина Казахстана;
- Удостоверение личности гражданина Киргизии;
- Водительское удостоверение гражданина Киргизии;
- Паспорт гражданина Таджикистана;
- Заграничный паспорт гражданина Таджикистана;
- Заграничный паспорт гражданина Украины.
Выбор соответствующего типа документа для распознавания осуществляется передачей в механизм распознавания нужного типа документа. Соответственно, в пользовательском интерфейсе пользователь должен явно указать тип распознаваемого документа. Определять шаблон автоматически механизм распознавания не умеет.
ABBYY PR SDK представляет собой набор функций (порядка 10ка), обеспечивающий передачу изображения в движок распознавания и получения результатов. Результаты содержат найденные на удостоверении личности области (координаты областей), распознанные данные, качество (уверенность) распознавания в процентах.
Также движок распознавания умеет считывать машинно-читаемую зону загранпаспортов, что даёт возможность обрабатывать загранпаспорта всех стран, которые являются членами ИКАО (International Civil Aviation Organization, Международной организации гражданской авиации).
Машинно-читаемый паспорт — это машинно-читаемый документ путешественника (MRTD, machine-readable travel document), с данными, кодированными специально для оптического распознавания текста. Впервые, данное усовершенствование предложила международная организация гражданской авиации 1968 году. Машинно-читаемые документы должны были значительно ускорить выписку авиабилетов, прохождение границы, контроль паспортов. В 1980 году вышла первая версия документа Doc 9303 MRTD, описывающего формат MRZ (МЧЗ – машинно-читаемой зоны). Первый паспорт с кодированной информацией по стандарту Doc 9303 был выдан в 1981 году в Соединённых Штатах и с тех пор формат стал завоёвывать популярность.

Затем появился формат MRV – machine readable visas. В 2004 году предложен ePassport – электронный паспорт, основанный на сертификатах электронной подписи, полностью кодированный в электронном виде паспорт, то, что мы сейчас называем «биометрический паспорт». Однако, считывание биометрических данных не относится к распознаванию текста и требует специализированного оборудования, тут уже простым настольным сканером не обойтись. В России правила формирования машинно-читаемой зоны утверждены приказом ФМС от 15 октября 2012 года №320 и определены в приложении №15. Данные правила сходны с требованиями Doc 9303, однако, отличаются в некоторых деталях.
Продукт хорошо документирован, описаны все функции, параметры вызовов, настроек и т.д.
Удобство встраивания ABBYY SDK можно условно оценить на 5.
При этом, существует ограниченная возможность управления процессом распознавания, управлять качеством изображения, очисткой и т.д.
Качество распознавания ABBYY PR SDK
Для оценки качества распознавания нами было протестировано распознавание 12 образцов паспортов РФ, которые были в наличии. Образцы не подготавливались специально, а были выбраны из тех что имелись ранее, часть из них были отсканированы, часть получены фотокамерой мобильного телефона. Расположение горизонтальное, без искажений.
- 9 изображений были распознаны корректно;
- Одно изображение не распознано с ошибкой;
- Из трёх паспортов не была извлечена ключевая информация – фамилия, имя, отчество.
Данные извлекаются независимо от разрешения переданного изображения, однако при определённом пороге (порядка 150dpi) качество распознавания резко падает вплоть до 100% ошибок.
Распознавание образцов, полученных непосредственно со сканера, при настройке яркости и контрастности изображения позволяет обеспечить практически 100% извлечение данных.
Механизм распознавания ABBYY PR SDK чувствителен к повороту изображения в полях АДРЕС, КЕМ ВЫДАН. При повороте или наклоне изображения появляются ошибки извлечения данных.
Время обработки изображения – порядка 4000 – 5000мс. При оценке времени мы учитывали необходимость движку «разогнаться», считать лицензию и т.д., так как первый запуск мог быть значительно дольше, до десятков секунд.
Smart Engines Smart IDReader
Продукт Smart IDReader представляет собой набор разработчика Software Development Kit непосредственно встраиваемый в конечное решение. Возможен только вариант встраивания в код прикладного программного обеспечения, функционирование как отдельный веб-сервис из коробки невозможно. Однако, есть решение для мобильных продуктов — в AppStore и GooglePlay выложены демо:
https://itunes.apple.com/ru/app/smart-idreader/id1157877082?mt=8
https://play.google.com/store/apps/details?id=biz.smartengines.smartid
Есть решения для распознавания из видеопотока, и на различных операционных системах, таких как iOS, MacOS, Windows, Linux, МЦСТ Эльбрус (Oh my God!!!).
Размер развёрнутого решения извлечения данных составляет 40 Мб.

Тестируемое программное обеспечение Smart IDReader, путём передачи соответствующих флагов в функцию распознавания позволяло обрабатывать:
- Паспорт
- СНИЛС
- Водительские удостоверения
- Свидетельство о регистрации транспортных средств (СТС)
- Любые документы с машиночитаемой зоной (MRZ)
- Банковские карты — кредитные и дебетовые
С сайта можно разработчика можно узнать, что Smart IDReader понимает водительские права, удостоверение о регистрации транспортного средства, СНИЛС, пластиковые карточки и другие документы. Правда, как включить это нигде не документировано. Анализ содержимого дистрибутива наводит на мысль, что шаблоны распознавания кодируются в виде описаний и правил на JSON, но, опять же, это нигде не документировано и инструментов настройки вендор не предоставляет. Правда разработчик готов сделать для вас любой шаблон по заказу под конкретный проект.
Решение для разработчика не документировано, передаётся как библиотека DLL и h-файл, для связывания с кодом С++.
С одной стороны, для людей неподготовленных, встраивание системы распознавания от Smart Engines может представлять некоторые трудности, с другой – разработчик гораздо более гибок в технической поддержке и готовности подстраивать продукт под ваши нужды.
Как недостаток, можно отметить отсутствие поддержки языков ближнего зарубежья – если вам потребуется такое решение, то выстроить его на Smart IDReader вряд ли быстро получится.
Удобство встраивания решения можно условно оценить на 3.
SmartID «из коробки» не обладает возможностью управления процессом распознавания, управлять качеством изображения, очисткой и т.д.
Качество распознавания Smart IDReader
Для оценки качества распознавания нами было протестировано распознавание тех же образцов паспортов РФ, которые были в наличии. Все изображения были распознаны, информация извлечена, процент ошибок незначительный.
Нами были протестированы ряд старых и новых образцов паспортов РФ. Распознавание образцов, полученных непосредственно со сканера, аналогично решению распознавания от Аби, при настройке яркости и контрастности изображения позволяет обеспечить практически 100% извлечение данных.
При определённом пороге (порядка 150dpi) качество распознавания резко падает вплоть до 100% ошибок.
Время обработки изображения – порядка 500-700мс., что существенно быстрее распознавания Abbyy PassportReader. Такое низкое время распознавания можно было бы объяснить прямым встраиванием библиотек в код тестового приложения. Не происходит маршалинг данных через SOAP, сериализация-десериализация и т.д. Однако, ради чистоты эксперимента мы протестировали встраивание Abbyy PassportReader в толстый клиент – время распознавания осталось примерно тем же, порядка 4-5 секунд. Это странно, но, видимо, такова специфика работы движка.
Выводы
Анализ двух механизмов распознавания приведён к баллам и обозначен в таблице:
| № п/п | Критерий | ABBYY PR | Smart IDReader |
| 1. | Удобство встраивания | 5 | 3 |
| 2. | Документация | 5 | 2 |
| 3. | Качество распознавания случайных изображений | 3 | 4 |
| 4. | Качество распознавания изображений со сканера при соответствующей настройке | 4 | 4 |
| 5. | Время обработки изображения | 3 | 5 |
| 6. | Набор шаблонов и мультиязычность | 5 | 3 |
| 7. | Размер установленного решения | 3 | 4 |
| Итого | 28 | 25 |
Оба механизма обладают примерно равными возможностями в части распознавания и извлечения данных. При этом можно отметить следующие отличительные особенности, важные конечному потребителю:
- Abbyy PR распознаёт больше языков и форм документов;
- Abbyy PR проще развёртывается и встраивается, более закончен как продукт, техническая поддержка на высоте. Компания Аби обладает непоколебимым авторитетом в области распознавания текстов.
- Smart IDReader работает значительно быстрее, это может быть критичным на больших объёмах документов;
- Декларировано, что Smart IDReader умеет распознавать видеопоток. Это может быть использовано в определённых сценариях;
- Smart IDReader умеет работать на мобильных устройствах и различных, даже экзотических (МЦСТ «Эльбрус»!!!) операционных системах.
Конечно, в итоге надо принимать решение на основе вашей задачи и требований к создаваемому программному обеспечению, выделенного бюджета, модели лицензирования, существующей инфраструктуры.